

全球人工智能(AI)运算能力与效率需求急剧攀升的浪潮下,由ChatGPT开发商OpenAI所规划的庞大“星际之门”(Stargate)计划,已成为驱动全球内存产品市场结构性变革的核心催化剂。这项耗资巨大的计划,对内存芯片的需求达到前所未有的水准,迫使供应链加速创新,并重新定义了从高带宽内存(HBM)到标准动态随机访问内存(DRAM),乃至固态硬盘(SSD)的分工与价值。
2024年,全球内存市场迎来关键转折点。根据路透社报道,韩国两大内存厂商──三星电子(Samsung Electronics)与SK海力士(SK Hynix),已正式签署意向书(LOI),将为OpenAI的数据中心供应关键的内存芯片。此举不仅象征着韩国芯片制造商正式加入“星际之门”的庞大供应链,更确立了内存在AI时代的战略地位。
由于韩国企业在全球内存市场中扮演着决定性的角色,两家公司合计掌握了全球DRAM市场约70%的市场占有率。更关键的是,在AI服务器和数据中心不可或缺的核心零部件HBM领域,韩国企业更是拥有近80%的绝对领先地位。在AI加速运算需求爆炸性增长的环境下,HBM已成为解决庞大算力需求的理想核心零部件。
然而,“星际之门”等超级AI项目对内存的需求已不再是单纯的容量叠加,而是对速度、容量、成本、效率的综合挑战。AI工作负载的特殊性,尤其是在模型推论阶段,正推动内存架构从传统的单一内存池,走向精细化、分层化管理的“AI内存分级”时代。
AI工作负载对内存的需求分级AI模型,特别是大语言模型(LLM),对数据记忆的需求类似于人类大脑,必须有不同层次的“记忆”来处理即时、短期和长期的资讯。根据市场消息指车,AI时代对内存需求因数据被细分为三个主要层级,每个层级对应不同的内存产品,这也决定了未来内存市场的产品组合与营收结构。
首先是HBM主要存储实时记忆数据。由于HBM具有极高的带宽与读写速度,但容量相对有限,因此它用于处理“极热数据”与“即时对话”,这类数据对延迟要求极高。HBM的容量范围大约在10GB至百GB级。在AI服务器中,HBM是搭配GPU处理器提供核心算力的关键。其次在DRAM方面,将作为短期记忆数据。它的速度相对快、容量较大,在服务器中常利用新型高速界面协议CXL延伸系统主内存,将数TB的DDR主内存汇集起来,形成大容量缓存。DRAM主要存储“热数据”与“多轮对话”,容量约在百GB到TB级。
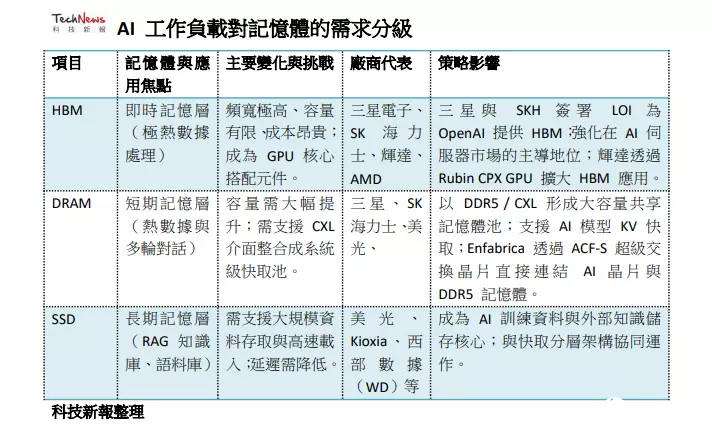
最后是SSD扮演长期记忆角色的状况,其用于存储外部知识。SSD容量极大,范围约在TB级到PB级,主要用于存储“历史对话”、“RAG知识库”以及“语料库”等热温数据。如此的内存分级模式显示,未来AI数据中心将是HBM、DRAM和SSD协同运行的复杂系统,而“星际之门”对规模和效率的极端追求,将加速这一分级架构的普遍部署。
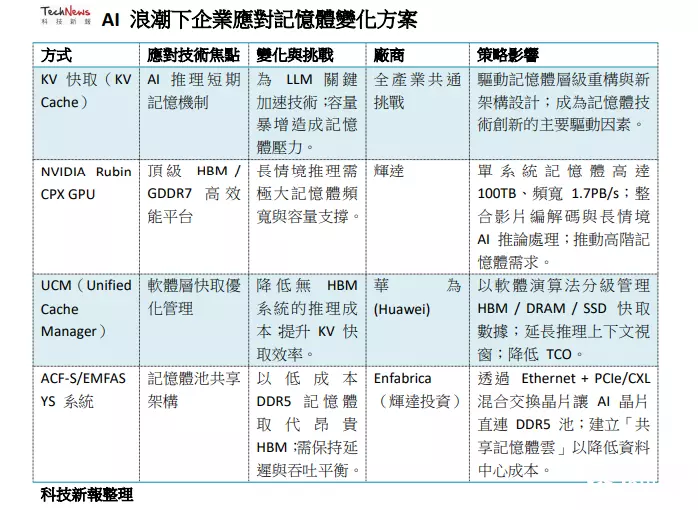
KV缓存为AI模型的短期记忆,解决方案成产业观关注焦点而在AI市场需求爆发的情况下,带动内存容量需求暴增的关键技术之一,便是大语言模型在推理阶段使用的“注意力机制”及由此衍生的“KV缓存”(KV Cache)机制。现阶段在AI推理过程中,模型会用到类似人脑的注意力机制,必须记住查询中重要的部分(Key)以及上下文中重要部分(Value),以便回答提示。传统上,如果每处理一个新的token(新词),模型必须针对先前处理过的所有token重新计算每个词的重要性(Key与Value),以更新注意力权重,过程极为耗时。而为解决此瓶颈,LLM被加入KV缓存机制。KV缓存类似于学生做笔记的概念,它能将先前的重要资讯(Key与Value)存储在内存中,免去每次重新计算的成本,从而将token处理与生成速度提升数个数量级。
KV缓存被称为“AI模型的短期记忆”。它使得模型能记住之前处理过的内容,无论用户重启讨论或提出新问题,都不必从头开始重新计算。这让AI能提供长格式语境,并能随时了解用户说过的、推理过的、提供过的内容,为更长、更深入的讨论提供更快、更缜密的答案。然而,KV缓存带来的挑战是巨大的。因为上下文越长,需要的缓存就越大。即使是中等规模的模型,KV缓存也会迅速膨胀到每个会话多GB,这使得针对KV缓存的解决方案,成为各家硬件与软件供应商关注的焦点之一。
针对长场景推论与顶级内存配置需求,英伟达推出Rubbin CPX面对“星际之门”级别的长场景(context)处理需求,GPU大厂英伟达 (NVIDIA) 的划时代创新技术,直接锁定内存的高性能、高扩展性挑战。在新推出的Rubin CPX GPU上,其核心使命就是突破AI系统在“长场景”推论上的瓶颈。随着AI模型处理数百万词元的需求愈加常见(如长篇文件理解或一小时视频生成),Rubin CPX以全新设计打破限制,能在单一芯片上集成视频解码器、编码器与长场景推论处理,提供前所未有的速度与性能。

英伟达创办人暨首席执行官黄仁勋指出,Rubin CPX是首款专为大规模场景AI设计的CUDA GPU。该平台与Vera Rubin CPU及Rubin GPU协同运行,组成的Vera Rubin NVL144 CPX平台,单一机架下可提供高达8 exaflops的AI运算能力,性能是现有GB300 NVL72系统的7.5倍。为了支撑如此严苛的AI工作负载,Rubin CPX系统必须配备惊人的内存配置,100TB内存与每秒1.7PB的带宽,确保数据能以极高速流动。
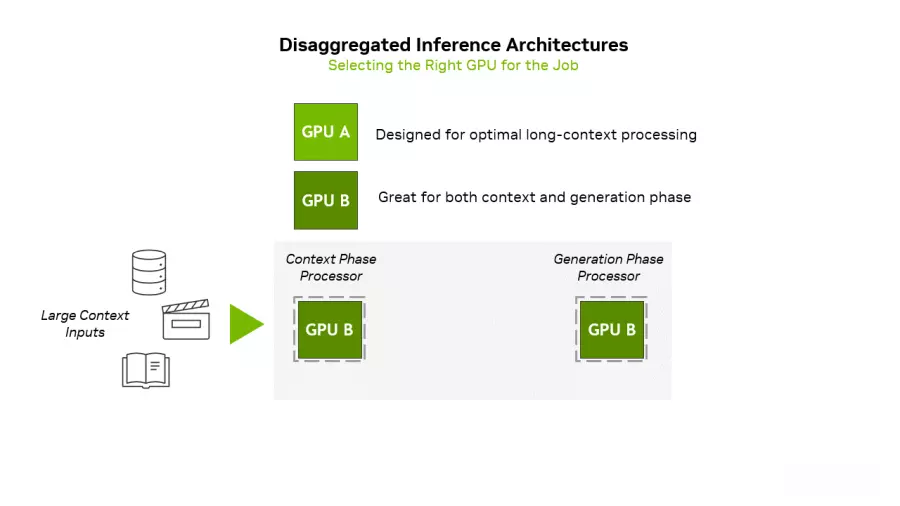
在单一芯片层面,Rubin CPX配备128GB GDDR7内存,采用NVFP4精度,算力达30 petaflops,能以极高能源效率处理大规模AI推论。与前代相比,Rubin CPX系统的专注力提升3倍,让AI模型能处理更长的场景串行,维持高性能而不降速。这样英伟达解决方案代表了内存市场的顶级需求:追求极致的速度与容量,并以高端HBM和GDDR7支撑,这对确保内存厂HBM业务的长期稳定增长提供了强劲保证。
Enfabrica从硬件架构试图降低数据中心内存成本另外,由英伟达支持的芯片创业公司企业Enfabrica则从硬件架构着手,试图降低数据中心高昂的内存成本。他们推出了EMFASYS软件搭配ACF-S芯片(又称为SuperNIC)的系统。也因为ACF-S本质上是一颗融合以太网络(Ethernet)与PCI-Express/CXL的交换芯片。Enfabrica创办人暨首席执行官Rochan Sankar指出,他们通过自研的专用网络芯片,可让AI运算芯片直接连接到装满DDR5内存规格的设备上。
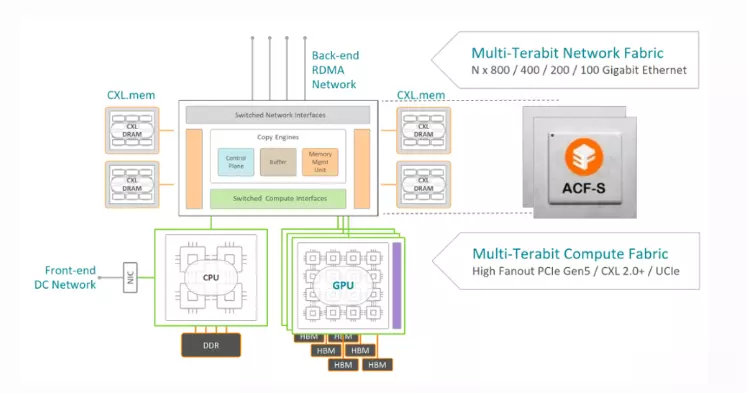
虽然DDR5传输速度不及HBM,但价格却便宜得多。Enfabrica的目标是拥有一个能以主机主内存速度运行、足以存放KV矢量与embeddings的超大共享内存池。外媒认为,若能加速用于AI推理核心的KV缓存,有望成为Enfabrica等同业期待已久的“杀手级应用”。且通过利用自研的专用软件在AI芯片与大量低成本内存之间进行数据传输,Enfabrica在保证数据中心性能的同时,有效控制了成本。这类架构创新突显市场对于利用低成本、大容量DDR5/CXL内存来满足KV缓存需求的强烈愿望。
整体来说,OpenAI“星际之门”计划以及整个AI产业对长场景、高效率推理的追逐,正对全球内存产品市场产生深远且复杂的影响。例如HBM成为不可撼动的战略核心、DRAM市场角色重新定义,以及SSD进入高性能AI架构,加上架构创新的决定性作用等。这使得星际之门所代表的超大规模AI推理需求,彻底改变了内存市场的供需生态。
(首图来源:Unsplash)配资炒股入门知识
华林优配提示:文章来自网络,不代表本站观点。
相关文章



热点资讯